
Image Localisation via Feature Matching
Published:
In this blog post, we would like to share some insights on our participation in the COMP90086 Computer Vision Project at the University of Melbourne (Semester 2, 2021).
The task of the project was to develop a method to estimate the coordinates from which an image was taken. The dataset for this task was published by the COMP90086 teaching team and consisted of a collection of images taken in and around an art museum (the Getty Center in Los Angeles, U.S.A.).
The training dataset contained a total of 7500 images labeled with their corresponding (x,y) coordinates. The test dataset for which the coordinates should be predicted contained 1200 images.
For our participation, we chose to use the pre-trained SuperGlue model to extract features from the images in the training set and match them with the images in the test set.
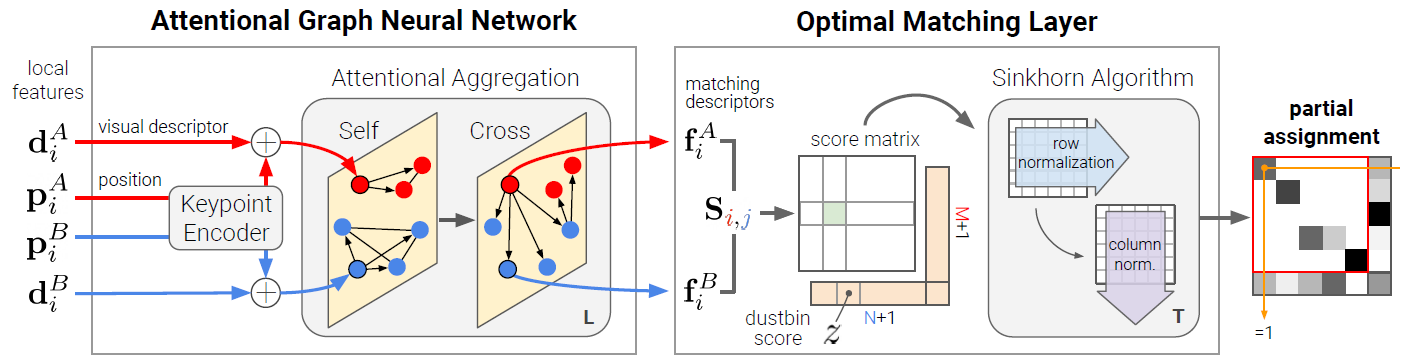
The image above shows the SuperGlue network architecture and is taken from the original SuperGlue paper by Sarlin et al. SuperGlue combines a graph neural network architecture and attention mechanism to match local image features by finding correspondences and dismissing unmatchable points. It consist of two main components:
In the first component (Attentional Graph Neural Network), SuperGlue borrows the self-attention mechanism from Transformer and embeds it into a Graph Neural Network. The attentional GNN leverages spatial relationships of keypoints and descriptors. It works by first employing an encoder to map keypoint positions $p$ and their associated descriptors $d$ into a single vector. In the next step, self-attention and cross-attention layers are used to generate more powerful representations $f$. This component consist of a total of 9 layers of self- and cross-attention with 4 heads each.
The second component (Optimal Matching Layer) creates an $M \times N$ score matrix and finds the optimal partial assignment between two sets of local features by using the Sinkhorn algorithm for $T = 100$ iterations.
The pre-trained SuperGlue model consisting of approx. 12M parameters has been implemented in PyTorch and available on GitHub. It can be amalgamated with any local feature detector and descriptor techniques such as SIFT and SuperPoint to extract sparse keypoints and perform matching. In our experiments, SuperGlue was able to estimate almost all correct matches while rejecting the majority of outliers.
Shown below is an example from the COMP90086 dataset. An example image from the test set is shown on the left, and the corresponding image from the training set is shown on the right. All detected matches are colored based on their predicted confidence in a jet colormap (red: more confident, blue: less confident).

By using the SuperGlue model, we managed to achieve a mean absolute error (MAE) of 5.15683, which put us on rank 9 out of 215 participants in the final Kaggle competition. The MAE score was calculated via the formula $MAE = \frac{1}{N} \sum_{i=1}^{N}abs(x_i - \hat{x}_i) + abs(y_i - \hat{y}_i)$.
A detailed write-up of the implementation details as well as other experiments that we performed (e.g. using SIFT or an Autoencoder architecture to match images based on their similarity) is available here, and if you are interested in further details, please refer to the following repository: COMP90086-Fine-grained-localisation.
References:
- Sarlin, P.-E., et al. (2020). Superglue: Learning feature matching with graph neural networks.
Authors:
- Matthias Bachfischer ([email protected])
- Nahid Tajik ([email protected])